神经网络笔记
关于BP网络的实现
有关神经网络宽度和深度的思考
- 加深神经网络一般来说是需要的,虽然现在更多的方向是进行防止过拟合的操作,但是在建立模型的初期,无论是特征量和特征复杂度还是有关数据相关性拟合上都是不好的。而且对于神经网络来说,增加宽度带来的是对特征本身的记忆,换句话说是记住特征量本身所携带的更多的“特征”,而增加深度则带来有关特征之间关系拟合的提升,能够更好地拟合出特征之间的关系。
关于TensorFlow实现LSTM的问题
- 为什么在数据初始化的时候不强制要求用 w[input_size, hidden_size] 进行处理:在生成 RNN 网络的函数中是带有这个转换的,因此不需要强制使用,在官方的解释里,inputs本身是一个长度为T(这个T和RNN的运算步长并没有确切的关系)的列表,而列表中的元素应当是形状为(bathcsize, inputsize)的Tensor或元组。
- (MNIST数据处理中)为什么要讲相同一行的数据转换到一起:通过查阅 RNN 网络生成代码我们可以发现,函数会根据我们划分的步长(for input in inputs)来处理数据,结合着这个链接来看,不难理解,一个 RNN 细胞中包含有多个单元,在大多数的文献和技术博客中,对于 hidden_size 的解释更多的是 LSTM 单元,我一时真的是转不过来这个弯,我的理解是,一个 RNNCell 就好像一个BP网络的神经元,这就造成了我对于 hidden_size 有一个极为错误而且矛盾的思路:如果 RNNCell 对应着 BP 网络的一个神经元,那么又改如何理解所有有关 RNN 讲解中为了更好理解 RNN 运行流程而进行的拆分呢?因为在 TensorFlow 实现RNN网络的样例中,对于 hidden_size 的解释是隐藏层的 LSTM 单元数(更加扯淡的直接说是隐层神经元的数目,对于这种人,我是能说,请自行百度神经元和细胞的关系以及 unit 到底是单元还是神经元)。其实现在想想,在论文中的RNN模型图解是这样的
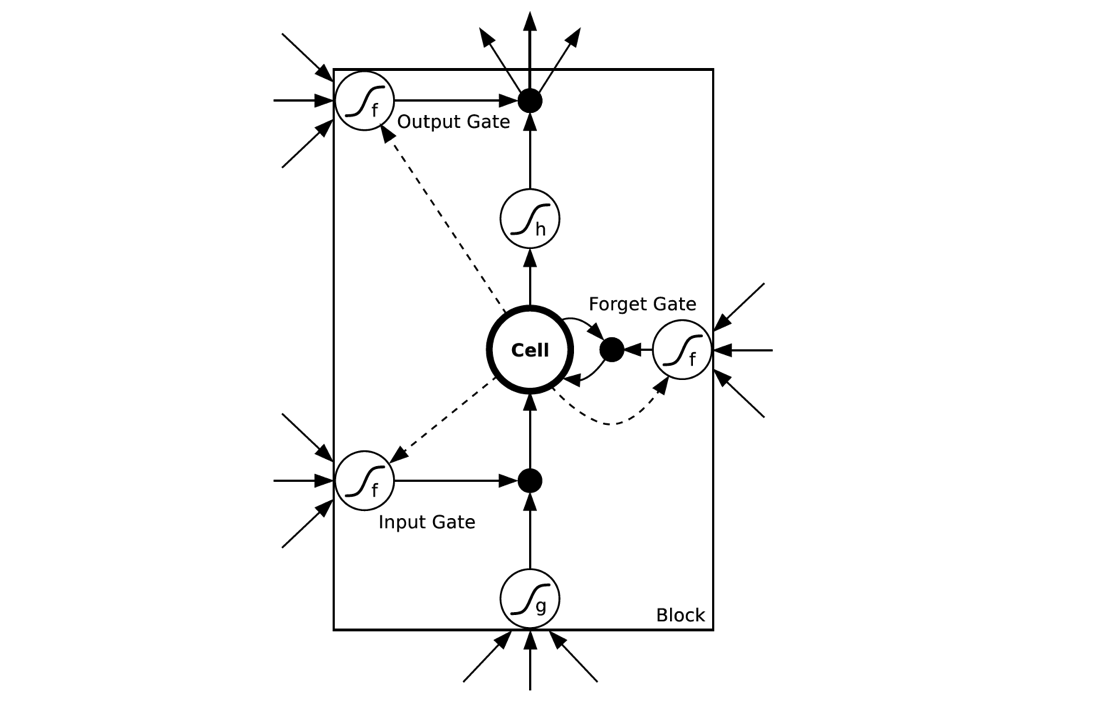
我们不难发现,RNN 细胞的输入输出其实是一个序列,外加 LSTM 的公式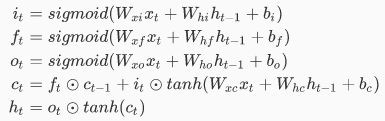
就可以知道每个门的实现其实对应着BP网络中的一层(这里一定要记住,所有的参数都是矩阵)只不过在技术博客的分享中有意无意忽略了这一点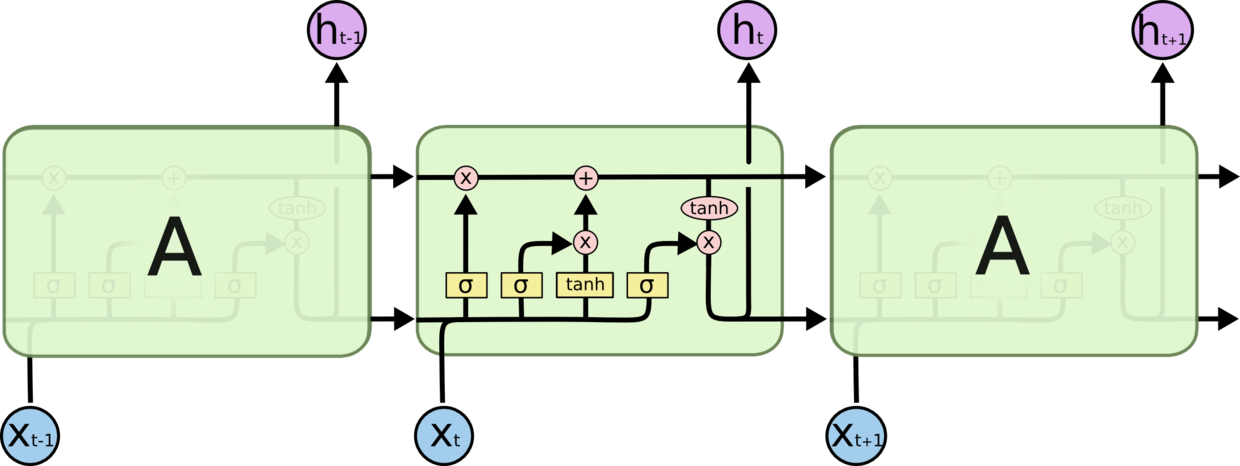
像我这种小白很容易跌落到对于实数的考虑中而不是将矩阵留在心间。另外一点,由于对于 RNN 的讲解是将 RNN 展开的,我承认,这样更加容易理解 RNN 的学习流程到底是什么样的,但是永远不要忘了,隐藏层中一层只有一个 RNN 细胞(一个细胞代表一个隐藏层,听起来是不是有种76的感觉),一个 RNN 细胞中包含一个 LSTM,而LSTM的unit_num是对于 LSTM 各个门的权重 & 偏置矩阵纬度的解释或者说 LSTM 单元才是真正对应着 BP 网络中的神经元。这样一来,对于 RNN 以及 LSTM 结构的理解就较为透彻了(这里我强烈推荐这个网站和这个网站来学习 LSTM,很受用)
有关强化学习
目前对于强化学习的理解包括马尔可夫决策过程(MDP)、贝尔曼方程、策略迭代、值迭代、蒙特卡罗强化学习、QLearning。最为让我纠结(18.1.7)的是在策略迭代和值迭代中书上采用了π(x,a),也就是在x状态下进行a行动的概率,这个和π(x)太容易让人迷惑。而且更坑的是,实际代码实现的方式中在策略评估阶段并没有进行行动a的迭代,而是直接采用π(x)取代a。而实际上π(x,a)代表的应当是在π(x)实际上并不唯一的状态下进行的更加一般化的策略评估和策略改进。在这里我们可以考虑一棵决策树,从根节点到叶子节点的最优路径实际上并不能保证唯一。而实际上采用π(x)确实有陷入局部最优的可能。但是我认为无论是否一般化,策略评估算法最为基础的思想还是对于样本矩阵中所有状态点之间的关系的学习,那么我们就可以利用计算期望中的概率的优势来优化算法,将对于点的遍历转化为对边的便利,最坏的情况和点遍历相同,而且具有一般性。具体的思路是通过链表纪录所有以状态x为起点的有向边,然后在遍历状态x的基础上遍历x链表即可。
另外一点,对于Q-learning中Q值更新的公式,有关状态转移概率书上并没有进行解释为什么不去考虑。而花费了很长时间才明白。Q值更新公式是蒙特卡罗和动态规划(干他妈的贝尔曼公式,老子老是以为是一个或一组具体的公式,早说是动归状态转移公式就不会这么麻烦了)的结合。
因为模型不可探知,我们也就无法知道状态转移概率,进一步来说,类似策略迭代或者是值迭代中最优子问题的解决就不是那么优雅自然,但是我们通过使用统计的方式,也就是蒙特卡罗方法,以随机采样的方式近似出最优策略是可行的,如果具有模型就好比我能够通过直径数据以及π的真实值算出圆的面积,那么蒙特卡罗就是我用无数的豆子洒在圆上,通过统计圆内外豆子的数量的比来近似估算圆的面积。相比模型已知的情况,使用蒙特卡罗方法是会有更多的计算量——或者说是更多的弯路。最为基础的蒙特卡罗是通过n次随机取样取平均值的方式来近似出最优解,但是为了最小化样本数目对于实际学习效果的影响,我们将均值1/n替换为alpha,很熟悉,就是我们的学习步长。而我纠结的点第一是因为对于蒙特卡罗了解不足,第二则是由于没有阅读实际实现代码,只是依靠书上或者网上的学习资料给出的伪代码造成了在多层循环的理解上犯了迷糊,单纯以为这几种方法循环总数是一样的。Qleaing是要用更多的样本数据来保证模型的正确性的,因此计算量更大。